9 MapReduce
Massive data parallelism
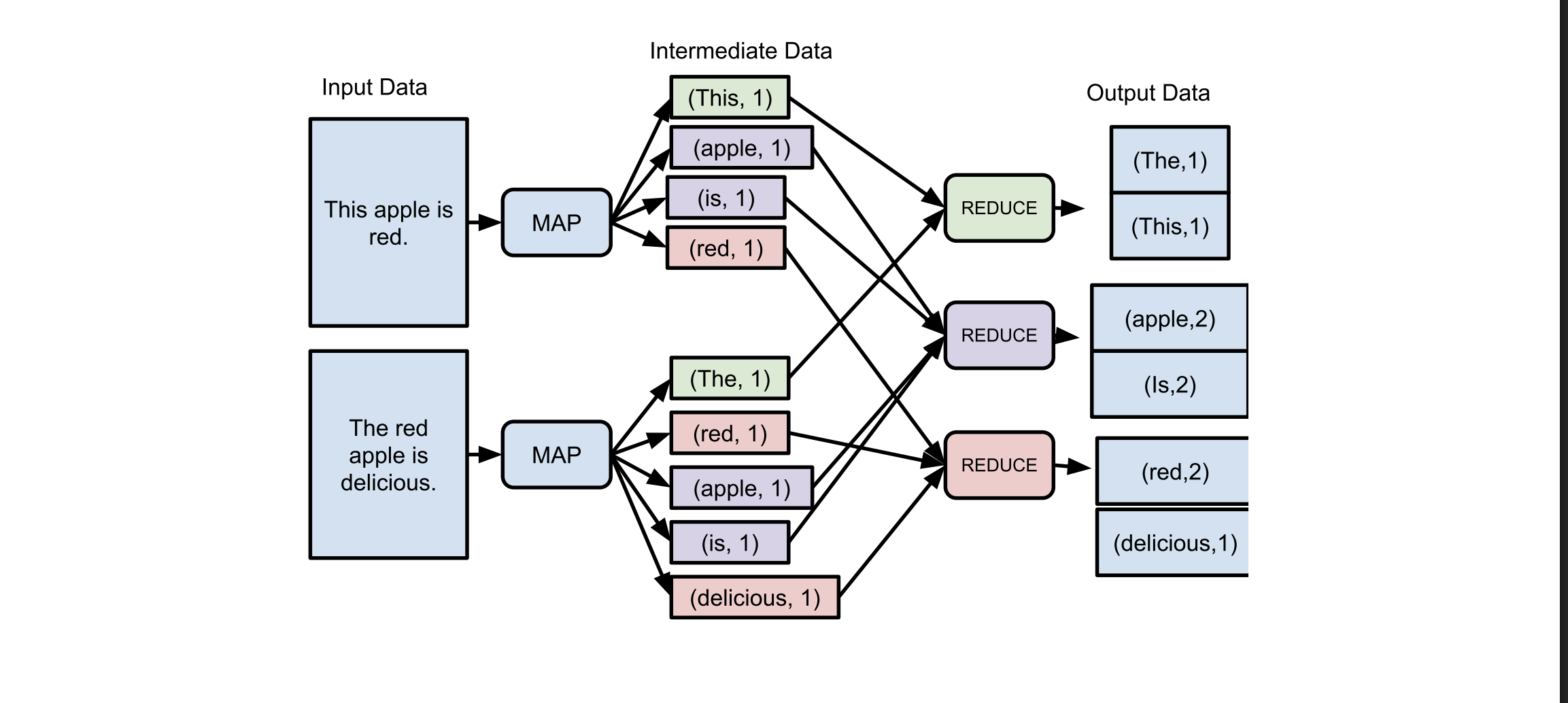
Map
- Takes in a (key, value) pair, produces a list of intermediate (key, value) pair
- (word, frequency) for each document
Reduce
- Takes a single intermediate key and a list of all associated values (of the same key)
- produce a final (key, final_value)
- All maps need to be complete before the reduce step
- How to guarantee that all occurrences of a single intermediate key go to a single worker?
- Hashing
MapReduce Coordinator
- orchestrates which worker runs which task and when
- maintain a data structure of all tasks
- if tasks are completed
- which worker is assigned to which task
MapReduce Worker
- regularly polls the coordinator for a task
- performs the task
Failures in MapReduce
What happens if the failed worker had previously completed map tasks?
- rerun failed worker's task on new worker
What happens if the failed worker had previously completed reduce tasks? - we do not need to re-run completed reduce tasks, as they are written to external storage
What happens if the coordinator fails? - request the client to restart computation
Stragglers
A worker is very slow. MapReduce is sensitive to stragglers
- Spawn tasks on multiple works simultaneously