19 Replication
Consensus
The property of achieving agreement on replicated state
Active Replication
Client broadcasts write requests to ALL servers; we worry about consistent ordering
Passive Replication
Client interacts with one server, which communicates to other replicas to stay in sync
Replicated State Machine (RSM)
send each operation to each server in order (operation must be deterministic)
State Transfer
send each modified state (however, states are usually large)
Primary Backup
- Clients communicate with a designated primary server for all reads/writes
- When the primary receives a write operation, it sends out the state change to all backup replicas to ensure they are up-to-date.
- When the primary fails, we must detect the failure, and have a backup server take it’s place as a new acting primary.
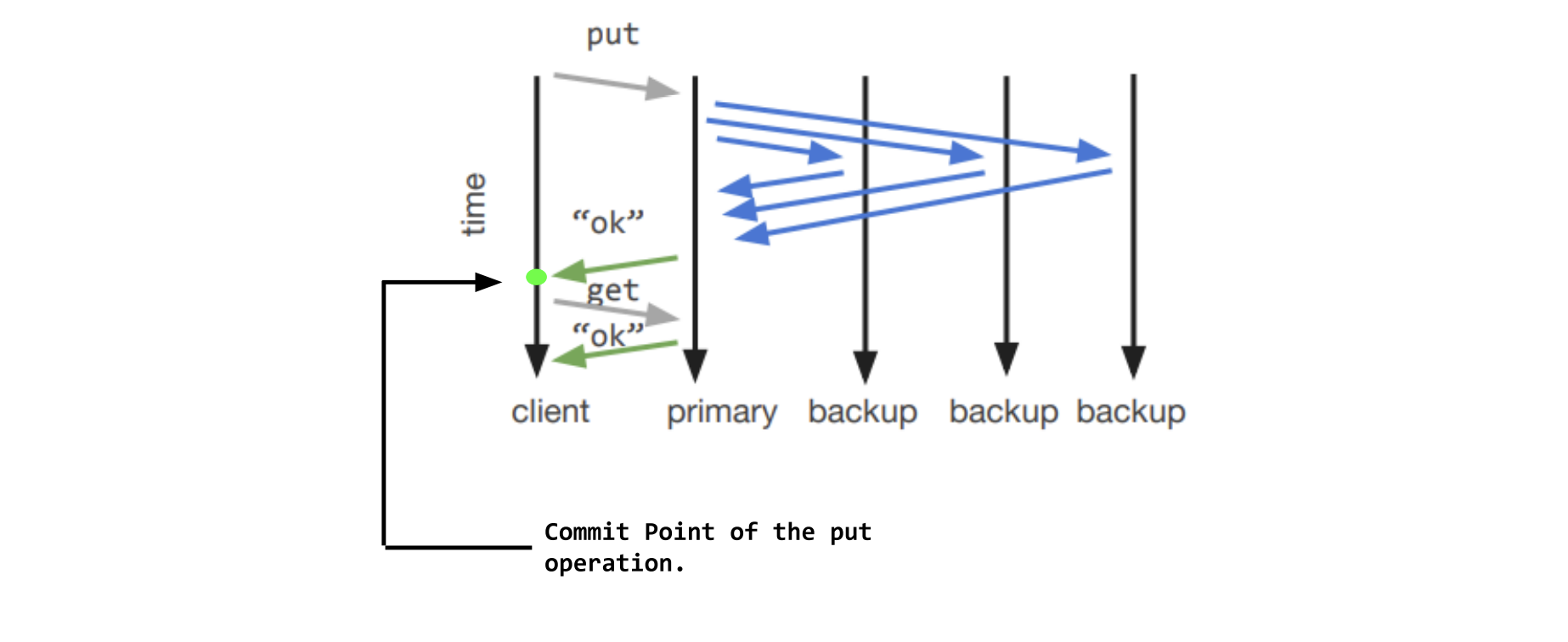
Only when all backups have ACKed the update (at commit point), primary copy will say OK to client. To guarantee strong consistency.
The order will be easily maintained as the primary copy can decided when it gets 2 incoming requests
Failures in Primary Backup
How do we know network failed or primary failed?
Use a configuration service (CFG) to manage Group Membership (Which servers are alive/dead). If CFG can contact, it's alive, otherwise treat it as dead. However that makes the CFG a bottleneck.
Downsides of Primary
- Performance - Primary server is the bottleneck
- deal with all client requests
- only say OK at commit point
- Failure - How to recover when primary fails while propagating replicas?
- have CFG delegate the up-to-date server as new primary (and propagate change)
- CFG choose a random new primary, roll back if inconsistent with newer
Chain Replication
- Clients communicate writes to the head server in the chain.
- The head server propagates the update only to the next server in the chain.
- Each middle server is responsible for propagating the update to the following server.
- The tail server is responsible for responding to the client.
a. When the tail server responds to the client, this is the commit point of the
operations in chain replication.
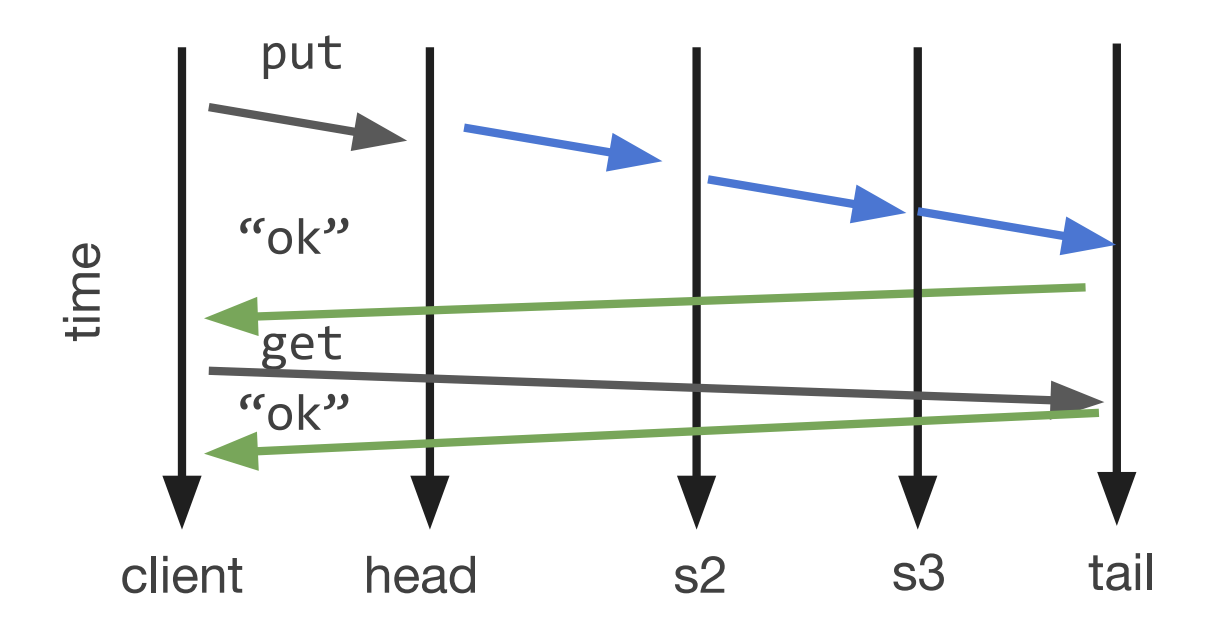
Read requests are sent to tail
Performance
- Better throughput (rate at which requests are processed in our system), but worse write latency (time it takes for a client to get a response to their request)
- If all read, 100% bottlenecked by tail server
- If all write, 100% bottlenecked by head server
Failures
- CFG detects failures in middle of chain, bypass failed server, communicates down the chain
- CFG detects head server failure, upgrades second server to head server and directs clients to the new head.
- CFG detects tail server failures, second to last server in the chain is the new tail and directs clients to the new tail
If a server fails at the wrong moment — say, while it’s halfway through sending or processing an update — the system needs to detect that and resend the missing update so the new replica can catch up.
Assumptions of Chain Replication
- Fail-stop servers: when it fails it fails
- what if there's a really slow worker? CFG doesn't exclude that
- CFG thinks a server is up but it's not communicating with its neighbors, the server is not available
- Single centralized configuration service does not fail
- suffers from a single point of failure
- Server Failure is Easy to Detect
- how to distinguish permanent and temporary failure?
Core tradeoff:
- any failed server stalls the system, so we want to declare a server to be failed as quickly
as possible! - but over-eager failure detector will waste time copying data
Performance
Primary Backup can have better write latency
● Communicates updates with backups in parallel
● More drastic with more replicas
Chain Replication has better throughput
● Splitting reads/writes between two nodes
● However: Same throughput as p/b when 100% reads
● However: Same throughput as p/b when 100% writes
Primary backup has a more complicated plan for
reconfiguration after failure.