15 Failures
Partial Failures
Part of the system of failing, other machine might be doing work while critical component fails; ends up in a strange state
Fault Tolerance
Property of a distributed system to be operational when partial failure
Availability
property of a system to be used immediately
Reliability
property of a system to run without failure
Availability v.s. Reliability
- Highly available, but unreliable - fails every minute but recovers immediately
- Highly reliable, but not available - Doesn't fail for years, but when fails, takes months to recover
MTTF (Mean Time To Failure) - average time until a component fails
MTTR (Mean Time to Repair) - average time needed to repair a component
MTBF (Mean Time between Failure) - MTTF + MTTR
- greater MTBF, more reliable
- MTTF/MTBF = availability of the system
Detecting Failures
Heartbeats
"Are you alive?" from all to all
In synchronous system, where message delivery times are bounded, we can be sure that a
suspected failure is a real failure.
challenges:
- Networks are partitioned, cannot all to all
- Partially synchronous system, cannot tell if message didn't get through or machine fail
- Result in false positives - remedy: ask neighbors if they have the same view
Gossip
Addition to heartbeats, also information about which machines we think are up
Failure Masking by Redundacy
Time Redundancy - If operation fails, retransmit request to the server
Physical Redundancy - extra hardware as back-up
RPC Semantics with Failures
Failures in RPC:
- The client crashes after sending request
- The request message is lost from client to server
- The server crashes before recieving request
- The response message is lost from server to client.
M (Send reponse)
P (Perform operation)
C (Crash)
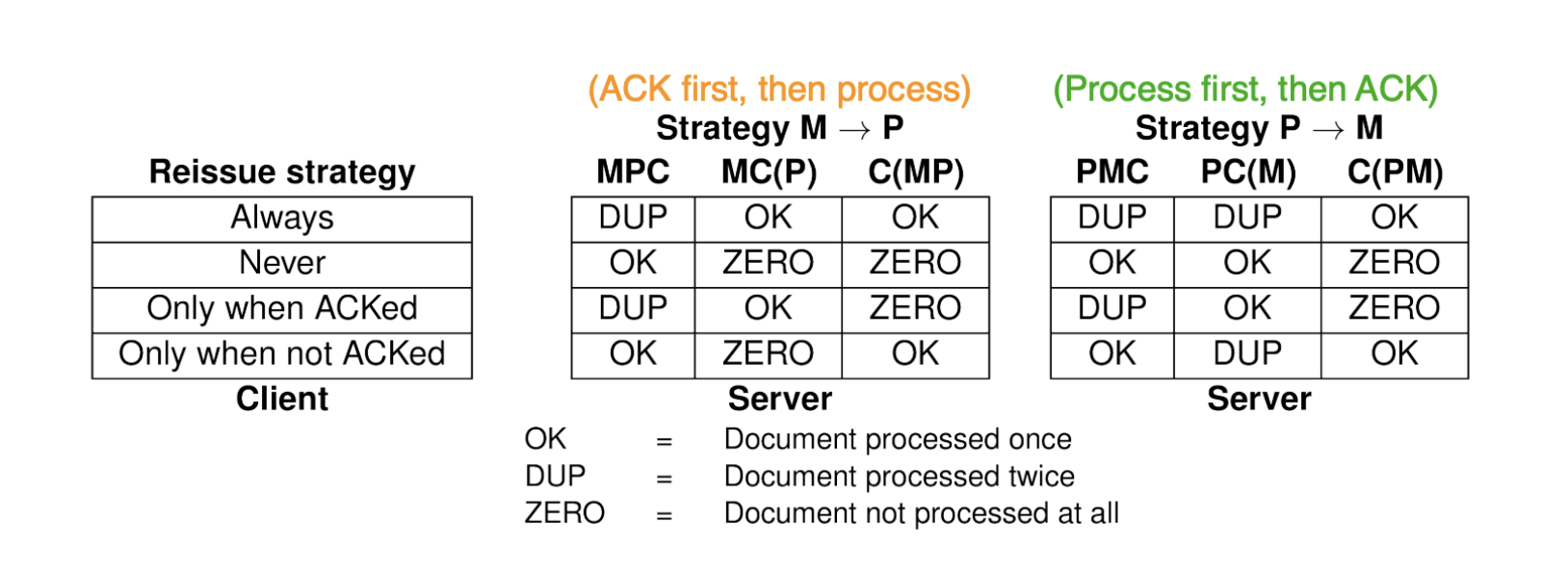
In No Setup is Exactly-Once Possible. However, when Always, we can acheive exactly-once if the system is idempotent